
※2024年7月13日:GoogleスプレッドシートでのWebスクレイピングのやり方を追加

今回は、あまり知られていないと思われる簡単で便利なエクセル※の小技を紹介します。
※Googleスプレッドシートのやり方も追加しました。
ExcelでWebサイトのテーブルデータを簡単に取得する
この技はWebサイトにあるテーブルデータをエクセルで簡単に取得する方法です。
ただし、単純に取得するだけではなくて、取得元Webサイトのテーブルをある程度自動的に加工しながら取り込むこともできるし、エクセルに接続情報も記録されるので、継続的に同じWebサイトから情報を取得したい場合に役立ちます。
ブログ作成用の情報収集やちょっとした調査業務に最適な方法だと思うので、ぜひご活用ください。
実際にテーブルを取得してみる
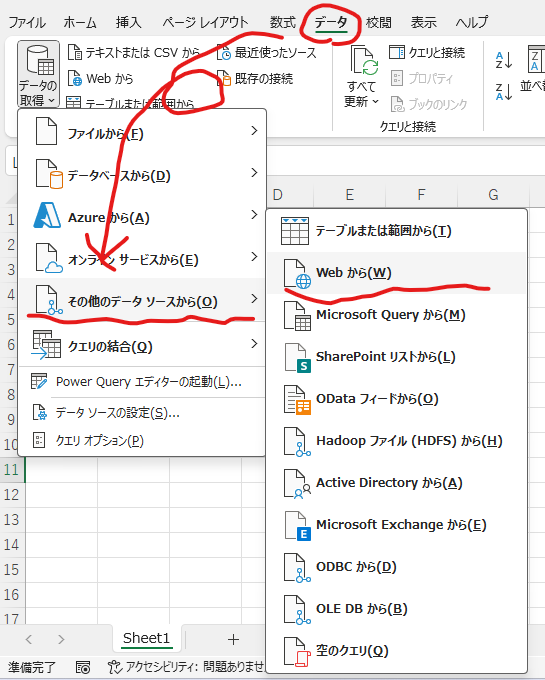
エクセルと既存データベースを接続したり、エクセルデータをデータベースとして使用したりするPower Query機能の一部ですが、今回ご紹介する機能は任意のWebサイトからデータベースを取り込むことができる機能です。
自動化するなど過度な利用は相手サーバーに大きな負荷をかけてしまう恐れがあるので、節度をもって使いましょう。
また、取得する情報の扱いにつきましては、くれぐれも取得先サイトの規約・規定等に従ってくださいませ。
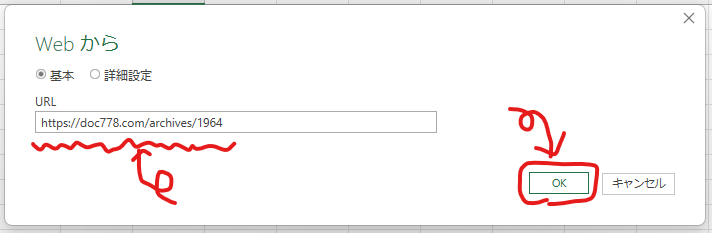
私は試していないのであれなんですが、「詳細設定」では、URLにパラメータを付けたり、ヘッダー情報を付与したりできるので、動的なWebサイトやWebアプリのHTTPリクエストのテストなどにも使えそうです。
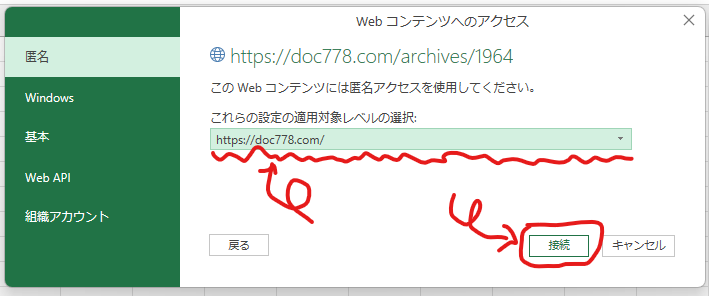
このダイアログボックスは、パスワードやAPIキーなどの認証・認可が必要なコンテンツへのアクセスのために使う設定です。
つまり、通常のWebサイトへのアクセスについては「匿名」で問題ありません。
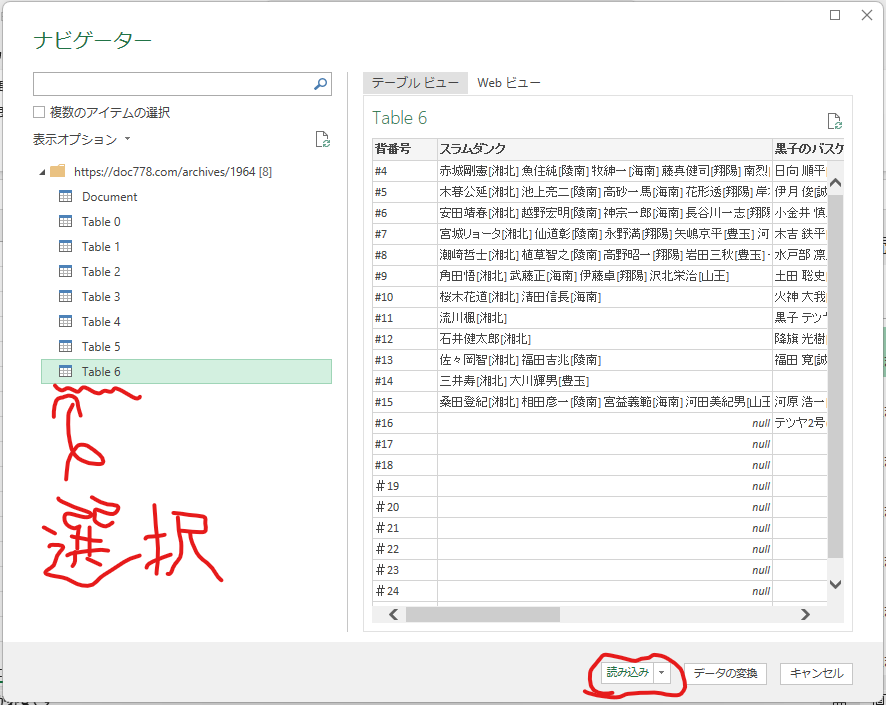
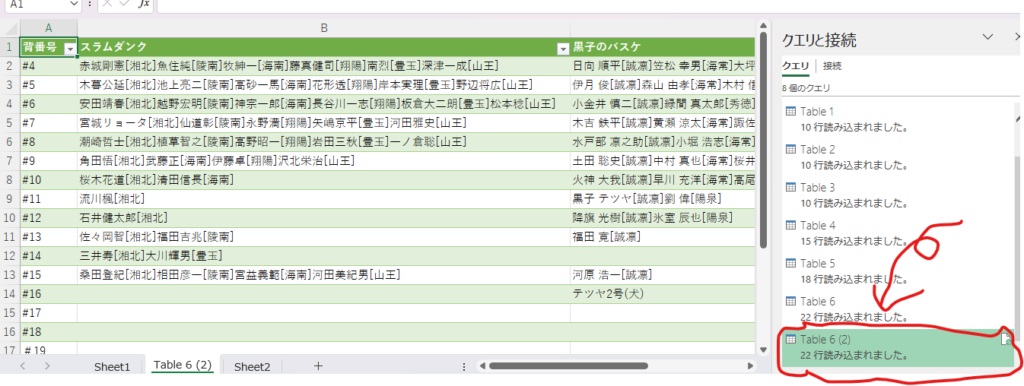
右側の「Table 1」等をダブルクリックするとPower Queryエディターが起動します。
Power Queryエディターでは、データ型を変更したり、行や列の削除ができるので、データのクレンジング(データクリーニング)を行うことができます。
また、クエリを保存することができるので、毎回同じクレンジングが必要なケースではその作業を自動化することができます。
GoogleスプレッドシートでWebスクレイピングする方法
IMPORTHTML 関数(インポートHTML関数)を使う
構文例) Webページ「https://doc778.com/archives/1964」の1番目の表をインポートする場合:
=IMPORTHTML("https://doc778.com/archives/1964", "table", 1)※https://doc778.com/archives/1964は私の管理しているページなので試しに使ってもらってOKです。
“table”の他には“list”を指定することもできます。このパラメータの後の「1」は何番目”table”かを指定する数字です。

任意の要素を取得したいときは
GoogleスプレッドシートではIMPORTXML関数(インポートXML関数)を使うことで、もっと詳細な情報を取得するできます。これはいわゆるWebスクレイピングというものです。
構文例) Webページ「https://doc778.com/nba-info」の見出しを取得する場合:
=IMPORTXML("https://doc778.com/nba-info","//*[@id='post-1138']/header/h1")※https://doc778.com/nba-infoは私の管理しているページなので試しに使ってもらってOKです。バスケットボールに興味があればついでに他のサイトも見てやってください。
“//*[@id=’post-1138′]/header/h1”の部分はXPathクエリというやつです。
- 右クリックして、「検証」をクリック
- 開発者ツールが表示されるので、取得したい部分を選んで右クリック
- 「コピー」をクリック
- 「XPath」をクリック
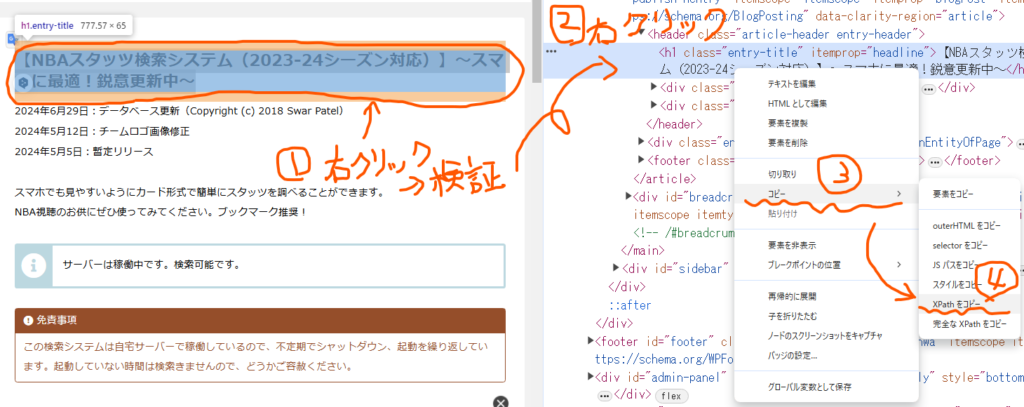
- クリップボードにコピーされた「XPathクエリ」を構文の該当するところに貼り付け

Webスクレイピングでのデータ取得を禁止しているサイトでは使用しないようにしましょう。
また、使用する際は、相手サーバーに大きな負荷をかけてしまう恐れがあるので、節度をもって使いましょう。
取得する情報の扱いにつきましては、くれぐれも取得先サイトの規約・規定等に従ってくださいませ。
以上です。尚、自分はXPathクエリは詳しくないので、参考にさせていただいた詳しそうな方の記事を貼っておきます↓
まとめ
Excelのデータベース機能は、難しいですが、SQLなどのプログラミング知識を必ずしも必要としないため、比較的学習のハードルは低いと思います。
データベースの学習用とブログのネタ集めには、ベストな選択肢ではないでしょうか。
Web上のテーブルデータを取得するだけなら本当に簡単なので、ぜひ使ってみてください。
製品版Microsoft365の購入先のご紹介(PR)
販売代理店で購入する

ECサイトで購入する
